
前言
之所以有着一篇文章,主要是看《细说PHP》这篇文章的时候,看到了介绍HTTP请求的部分,其中在介绍HTTP链接的各个阶段的时候,抛砖引玉的提了下UDP 和TCP,然后又一笔带过了其他的内容,这就让我产生了好奇心,所以我被迫临时恶补一下关于网络连接方面的基本知识。
这篇文章主要作记录用途,用于记录我看书过程中发现的既有误区,还有认为的比较重要的点。另外吐槽一下,《细说PHP》写的十分不错,700页的篇幅,详略得当,是PHP入门精品,唯一美中不足的是出版这本书的是一个补习机构,而且似乎已经跑路了。真的痛心疾首,也就是说第三版是不可能的了,PHP近7年的修改演变只能后续从官方手册了解了。
正文
网址
网址,准确的名字叫做URL(Uniform Resource Locator)统一资源定位符
URL有多种写法,根据访问的目标不同,URL的写法也会不同,访问不同的目标需要使用不同的方法,所需要的信息也有所不同,这就导致了URL格式上的差异:
//访问web服务器 使用http协议
http://user:password@xzyuse.space:80/index.html (用户名,密码,端口可以省略)
//访问ftp服务器 使用ftp协议
ftp://user:password@xzyuse.space:80/index.html (用户名,密码,端口可以省略)
//读取客户端本地文件
file://localhost/c:file.zip(localhost 可以省略)
//发送电子邮件
mailto://alistairblake007@gmail.com (协议 + 邮件地址)
//阅读新闻组的文章(现代浏览器已经不支持直接打开,需要专用软件才可以使用)
news://news.eternal-september.org/comp.protocols.tcp-ip (news://[服务器地址]/[新闻组名称])解析
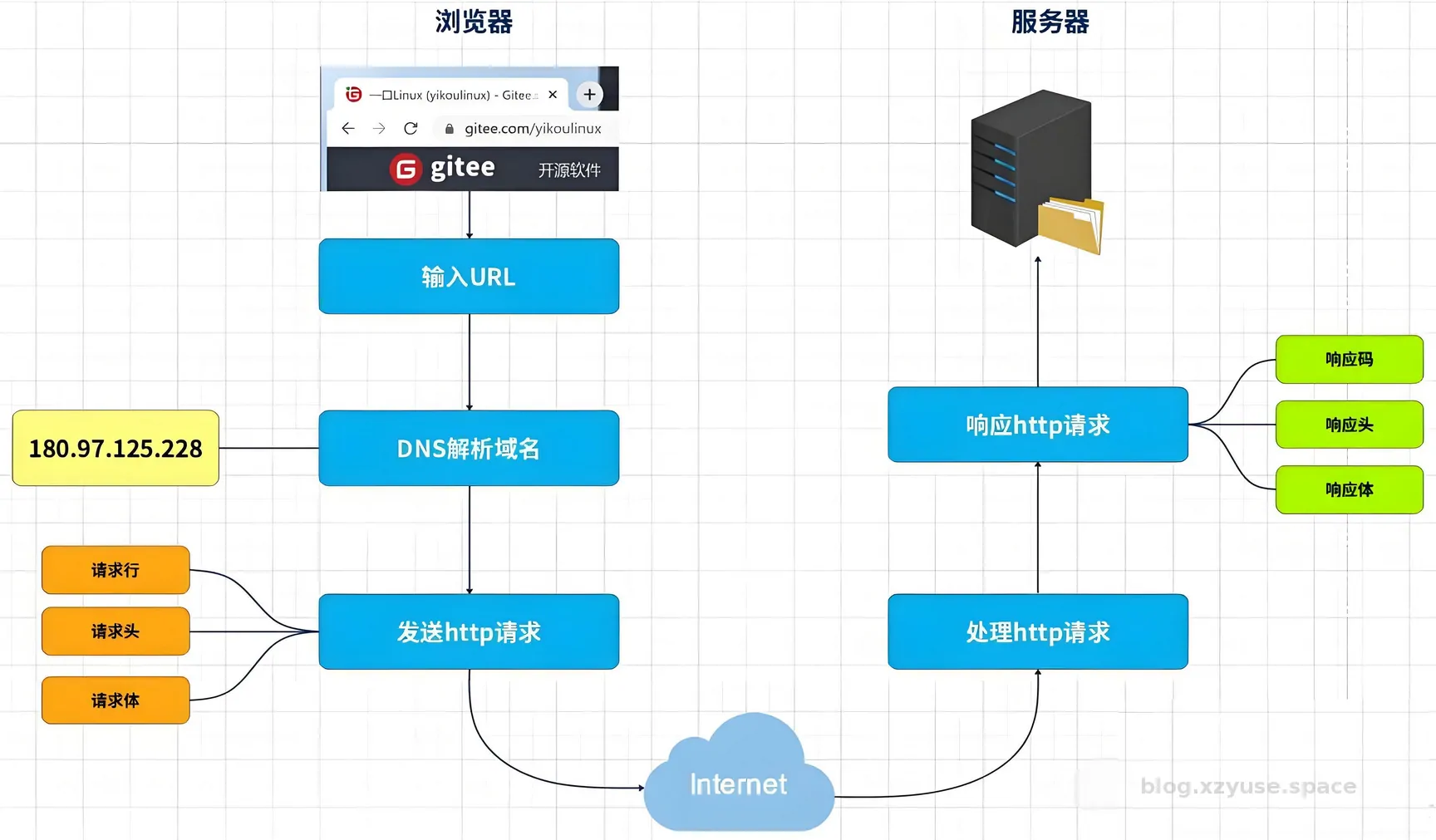
用户在网址栏输入网址后,浏览器随后开始在本地进行网址的结构化解析,首先是识别URL使用何种通信协议,因为这决定了后续的解析流程,假设浏览器确认该URL以 http 开头,即使用http协议访问web服务器,接下来会寻找 user:password 字段,直到读取到 @ 表示这个字段的结束,接下来浏览器会寻找 服务器域名:端口 字段,当读取到 / 表示这个字段结束,而后服务器会从 / 开始,将剩余的字符串当作文件路径。如此以来,浏览器的工作就完成了。如果没有 / 浏览器会自行补上一个 / 并且结束结构化解析。
浏览器在完成结构化解析后,会尝试建立https请求,浏览器将文件路径发送给服务器,这一部分交由服务器解析,无论是否带有 / 这一部分的解析交由服务器文件系统解析,如果一个路径以 / 结尾,文件系统会将其理解为一个目录,如果该目录不存在,服务器返回 403 Forbidden 或 404 Not Found ,如果目录存在,则寻找默认索引文件,通常是 index.fileformat ,如果不存在索引文件,但是服务器设置了允许目录浏览,会返回该目录的文件列表。“如果一个路径不以 / 结尾,服务器首先查找是否存在一个同名文件。如果存在,返回该文件。如果不存在文件但存在同名目录,服务器通常会返回一个 301 重定向到带尾斜杠的路径 /file/。客户端(浏览器)收到重定向后,会自动发起对 /file/ 的新请求,然后服务器再处理目录内的索引文件。”在文件系统看来,以 / 结尾表示目录,不 / 结尾就表示文件,但是具体到浏览器访问的时候,当文件不存在,但是同名目录存在的时候会自动触发一个重定向(这个行为可以通过服务器配置关闭。例如,在 Nginx 中,如果使用 try_files 指令,可能不会触发重定向,而是直接尝试其他后备选项。)。
这里的一大堆不需要掌握,网页开发者只需要明白,所有开发人员一般都会遵循规范,以 / 结尾的是一个目录,不以 / 结尾的是一个文件,但是偶尔也会为了美观,将 目录后的 / 省略,如果是域名后的 / 省略,是利用了浏览器的自动补全,如果是具体目录后的 / 省略,则是利用了服务器自发进行的301重定向。
这里必须说一下,为了完善解析这一部分的描述,耗费了我比较多的时间,做到了在不引入更多连接细节下最大化的原理诠释,更多的细节牵涉到,服务器软件,还有路由表,展开十分麻烦了,这里是最经典的情况下的分析,也就是仅仅考虑了服务器的物理文件系统的情况,不牵涉服务器软件还有路由表做的干涉。
http
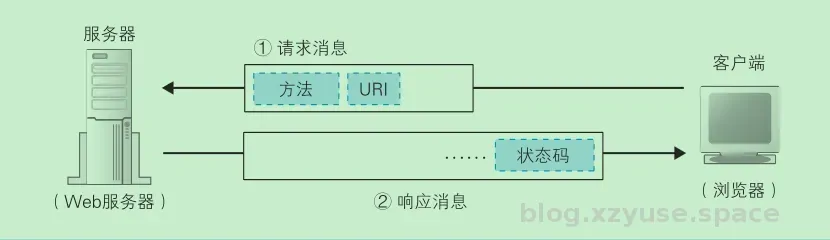
这上边是那本书上的插图,插一句嘴,因为那本书的描述太过于通俗,以至于简单的逻辑复杂化了,所以的博客提到的都是个人优化提纯的版本,不过有一说一,这个人的插图真的好赞。
在进行 http 通信前,客户端会与服务器经过三次握手建立 TCP 连接,随后通过 TCP 连接发送 http 请求,请求消息包含方法以及 URI (Uniform Resource Identifier,统一资源标识符。)是比 URL 更加宽广的概念,简单而言 URI 可以是 URL,也可以是其他的东西,例如 URI 既可以是 服务器上的一个 html 文件,也可以是一个 CGI 程序,对 Web 服务器程序调用其他程序的规则所做的定义就是 CGI,而按照 CGI 规范来工作的程序就称为 CGI 程序。例如 Apache 可以配置CGI规则:
AddType application/x-httpd-php .php #告诉 Apache:.php 文件由 PHP 模块处理,在执行这个操作之前,确保已经执行sudo apt install php libapache2-mod-php以确保php作为apache的一个模块运行。
DirectoryIndex index.php index.html #可选:设置默认首页当指向的是 CGI 程序的时候,这个程序必须具有可执行权限,这个使用宝塔的人就会比较熟悉,最常见的就是 755权限,所有者www,应用到全部子目录 这个描述,玩宝塔的人会比较熟悉,如果不进行这样的权限配置,即使 CGI 规则配置好了,也会因为没有可执行权限无法执行。如果使用 PHP,我们通常无需进CGI的配置,因为.php 文件默认就是由 PHP 执行的,这是 Apache 的标准配置,通常不需要额外设置。
接下来做着重介绍方法,方法表示的是让web服务器完成怎样的操作,最典型的就是读取URI表示的数据,和将用户填写的表单发送到URI所表示的程序中。常见的方法有:
在发送 Http 请求后,浏览器除了发送URI,方法,还会发送用来表示附加信息的头字段,头字段属于可有可无的附加信息。当服务器接收到客户端发送来的请求后,会利用其中的URI和方法做出响应的处理,并且将结果存放在响应消息中。
响应消息的开头是一个状态码,用来表示执行成功还是发生了错误,例如当我们尝试GET服务器上不存在的文件的时候,浏览器显示 404 Not Found 的消息,这就是因为服务器发送的响应信息中的状态码404。状态码后,是头字段和网页数据,相应信息发送回客户端,客户端收到后,浏览器会从消息中读出所需要的数据并且显示在屏幕上,到这Http的整个工作就完成了。
请求
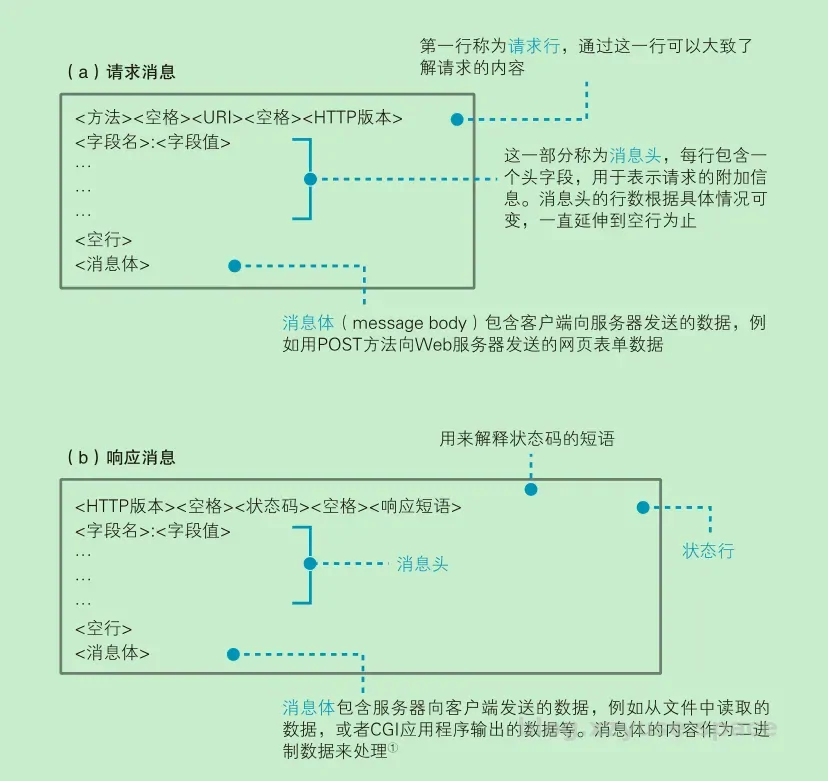
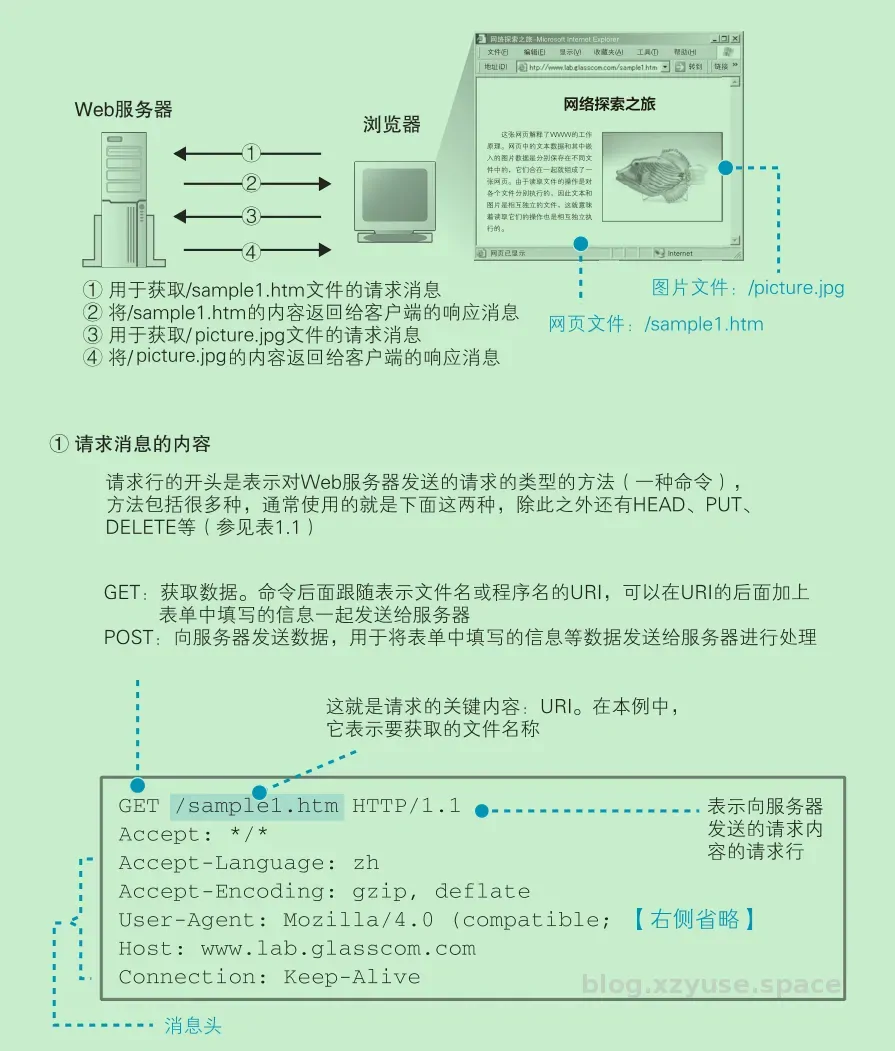
前边已经介绍了建立Http连接的基本流程(TCP连接,发送请求消息,接受响应消息,断开连接)。现在我们具体看看浏览器如何构造请求,以及一个http请求究竟是什么样子的。这里由于原作的图片太好,我就直接引用了,感谢原作作者。
在浏览器的使用场景下,主要有两个应用,第一个是请求页面,这是个时候需要使用 GET 方法,另一个是发送表单,既可以使用 GET 方法,也可以使用 POST 方法,但是需要注意到GET 方法能够发送的数据只有几百个字节,如果表单中的数据超过这个长度,则必须使用 POST 方法发送。下面的图显示的十分好,
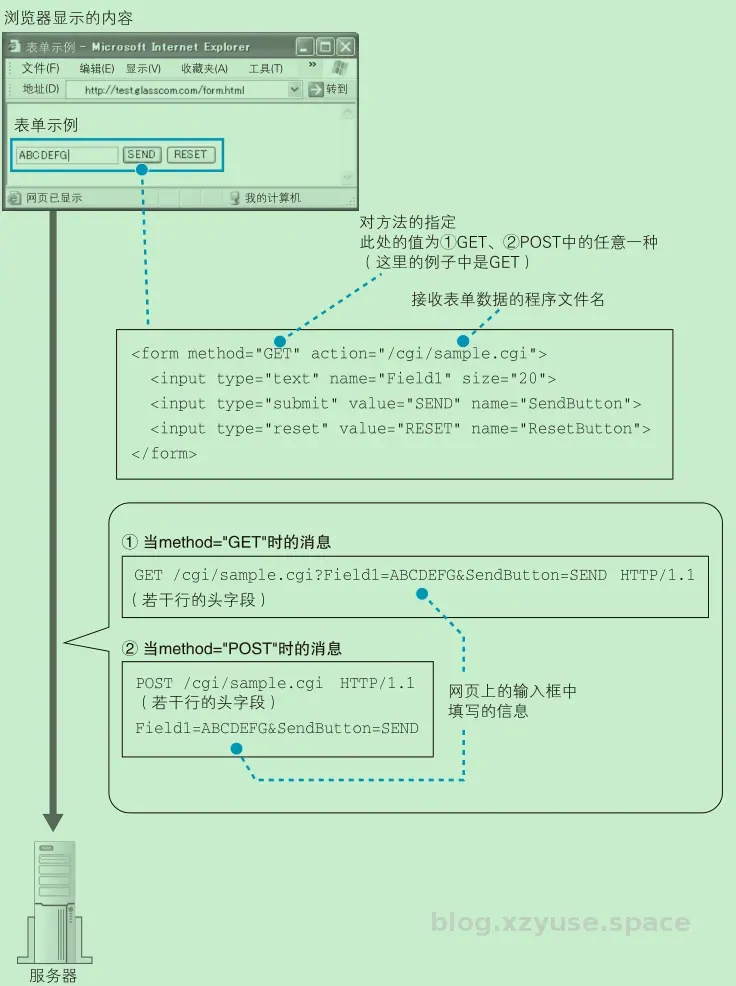
当使用 POST 方法时,需要将表单中填写的信息写在消息体中。到此为止,请求消息的生成操作就全部完成了。
响应
当我们将上述请求消息发送出去之后,Web 服务器会返回响应消息。关于响应消息我们将在第 6 章详细介绍,这里先粗略地了解一下。响应消息的格式以及基本思路和请求消息是相同的,在响应消息中,第一行的内容为状态码和响应短语,用来表示请求的执行结果是成功还是出错。状态码和响应短语表示的内容一致,但它们的用途不同。状态码是一个数字,它主要用来向程序告知执行的结果;相对地,响应短语则是一段文字,用来向人们告知执行的结果。
状态码的第一位数字表示状态类型,第二、三位数字表示具体的情况。下表列举了第一位数字的含义。
返回响应消息之后,浏览器会将数据提取出来并显示在屏幕上,我们就能够看到网页的样子了。如果网页的内容只有文字,那么到这里就全部
处理完毕了,但如果网页中还包括图片等资源,则还有下文。
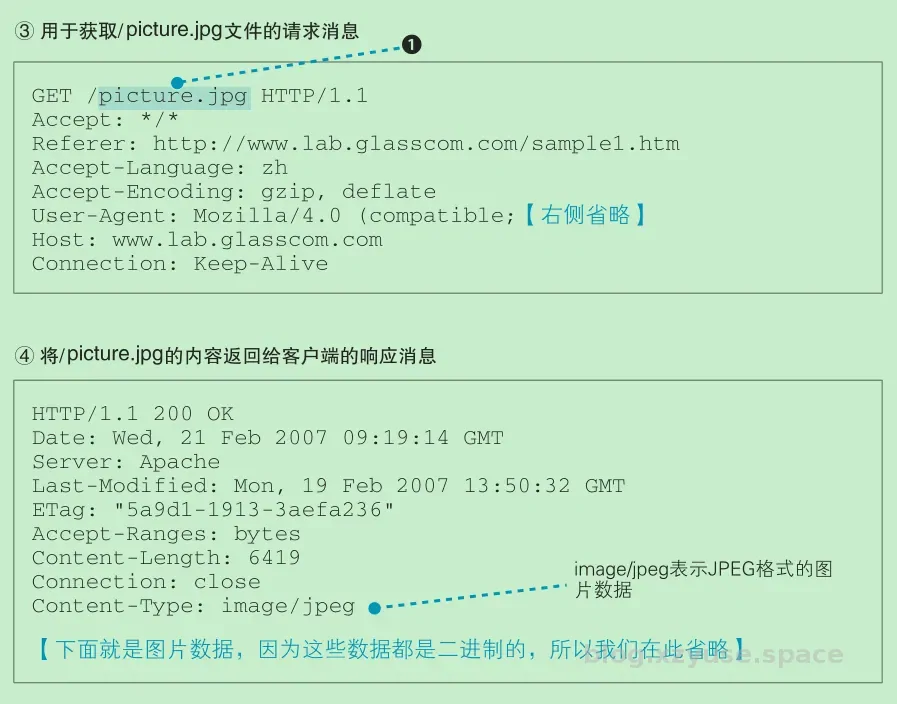
当网页中包含图片时,会在网页中的相应位置嵌入表示图片文件的标签A的控制信息。浏览器会在显示文字时搜索相应的标签,当遇到图片相关,的标签时,会在屏幕上留出用来显示图片的空间,然后再次访问 Web 服务器,按照标签中指定的文件名向 Web 服务器请求获取相应的图片并显示在预留的空间中。这个步骤和获取网页文件时一样,只要在 URI 部分写上图片的文件名并生成和发送请求消息就可以了。
由于每条请求消息中只能写 1 个 URI,所以每次只能获取 1 个文件,如果需要获取多个文件,必须对每个文件单独发送 1 条请求。比如 1 个网页中包含 3 张图片,那么获取网页加上获取图片,一共需要向 Web 服务器发送 4 条请求。
判断所需的文件,然后获取这些文件并显示在屏幕上,这一系列工作的整体指挥也是浏览器的任务之一,而 Web 服务器却毫不知情。Web 服务器完全不关心这 4 条请求获取的文件到底是 1 个网页上的还是不同网页上的,它的任务就是对每一条单独的请求返回 1 条响应而已。
由于原文的配图太好,所以我这里就直接引用了。

评论